

在前面我们简单介绍了lambda表达式,Java8旨在帮助程序员写出更好的代码, 其对核心类库的改进也是关键的一部分,Stream是Java8种处理集合的抽象概念, 它可以指定你希望对集合的操作,但是执行操作的时间交给具体实现来决定。
Java语言中集合是使用最多的API,几乎每个Java程序都会用到集合操作, 这里的Stream和IO中的Stream不同,它提供了对集合操作的增强,极大的提高了操作集合对象的便利性。
集合对于大多数编程任务而言都是基本的,为了解释集合是怎么工作,我们想象一下当下最火的外卖APP, 当我们点菜的时候需要按照距离、价格、销量等进行排序后筛选出自己满意的菜品。 你可能想选择距离自己最近的一家店铺点菜,尽管用集合可以完成这件事,但集合的操作远远算不上完美。
这里也使用了部分lambda表达式,在Java8之前你可能写的更痛苦一些。 要是要处理大量元素又该怎么办呢?为了提高性能,你需要并行处理,并利用多核架构。 但写并行代码比用迭代器还要复杂,而且调试起来也够受的!
新的API对所有的集合操作都提供了生成流操作的方法,写的代码也行云流水,我们非常简单的就筛选了离我最近的店铺。 在后面我们继续Stream更多的特性和玩法。
当你处理集合时,通常会对它进行迭代,然后处理返回的每个元素。比如我想看看月销量大于1000的店铺个数。
的操作是可行的,但是当每次迭代的时候你需要些很多重复的代码。将for循环修改为并行执行也非常困难, 需要修改每个for的实现。
从集合背后的原理来看,for循环封装了迭代的语法糖,首先调用iterator方法,产生一个Iterator对象, 然后控制整个迭代,这就是外部迭代。迭代的过程通过调用Iterator对象的hasNext和next方法完成。
而迭代器也是有问题的。它很难抽象出未知的不能操作;此外它本质上还是串行化的操作,总体来看使用 for循环会将行为和方法混为一谈。
另一种办法是使用内部迭代完成,properties.stream()该方法返回一个Stream而不是迭代器。
为了找出销量大于1000的店铺,需要先做一次过滤:filter,你可以看看这个方法的入参就是前面讲到的Predicate断言型函数式接口, 测试一个函数完成后,返回值为boolean。 由于Stream API的风格,我们没有改变集合的内容,而是描述了Stream的内容,最终调用count()方法计算出Stream 里包含了多少个过滤之后的对象,返回值为long。
你已经知道Java8种在Collection接口添加了Stream方法,可以将任何集合转换成一个Stream。 如果你操作的是一个数组可以使用Stream.of(1, 2, 3)方法将它转换为一个流。
也许有人知道JDK7中添加了一些类库如Files.readAllLines(Paths.get(“/home/biezhi/a.txt”))这样的读取文件行方法。 List作为Collection的子类拥有转换流的方法,那么我们读取这个文本文件到一个字符串变量中将变得更简洁:
这里的collect是后面要的收集器,对Stream进行了处理后得到一个文本文件的内容。
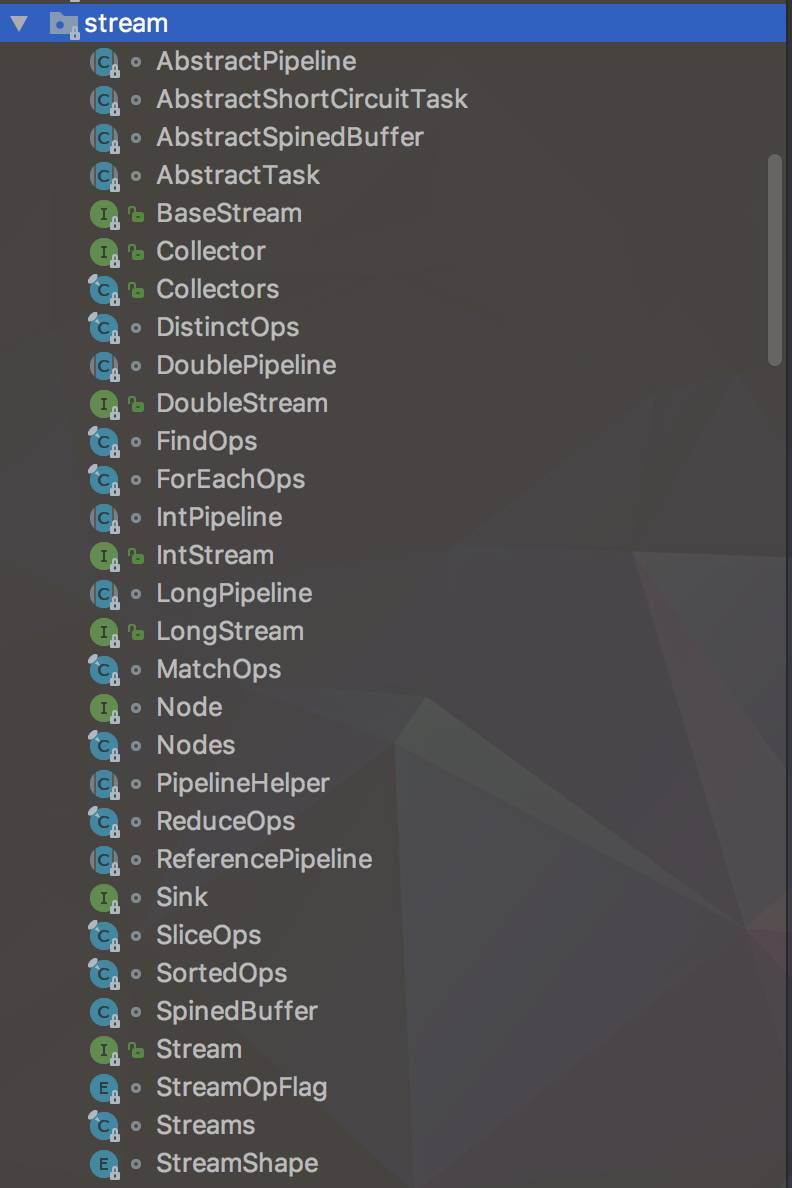
java.util.stream.Stream中定义了许多流操作的方法,为了更好的理解Stream API掌握它常用的操作非常重要。 流的操作其实可以分为两类:处理操作、聚合操作。
处理操作:诸如filter、map等处理操作将Stream一层一层的进行抽离,返回一个流给下一层使用。
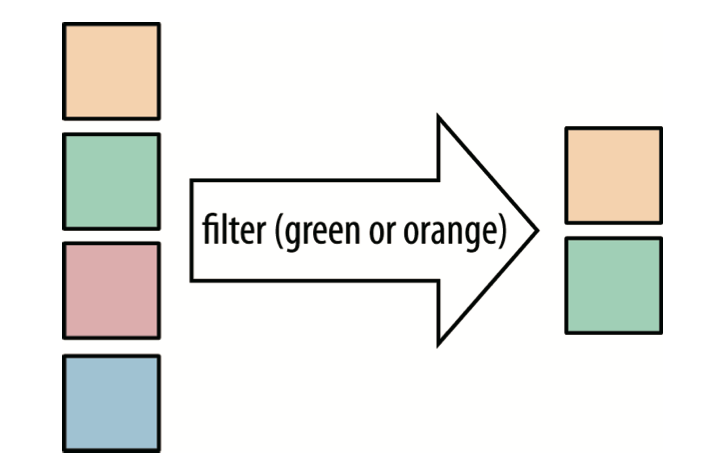
有时候我们需要将流中处理的数据类型进行转换,这时候就可以使用map方法来完成,将流中的值转换为一个新的流。
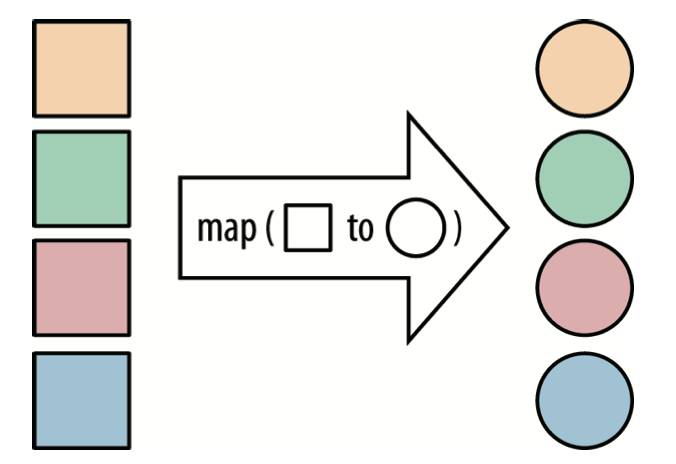
传给map的lambda表达式接收一个Property类型的参数,返回一个String。 参数和返回值不必属于同一种类型,但是lambda表达式必须是Function接口的一个实例。
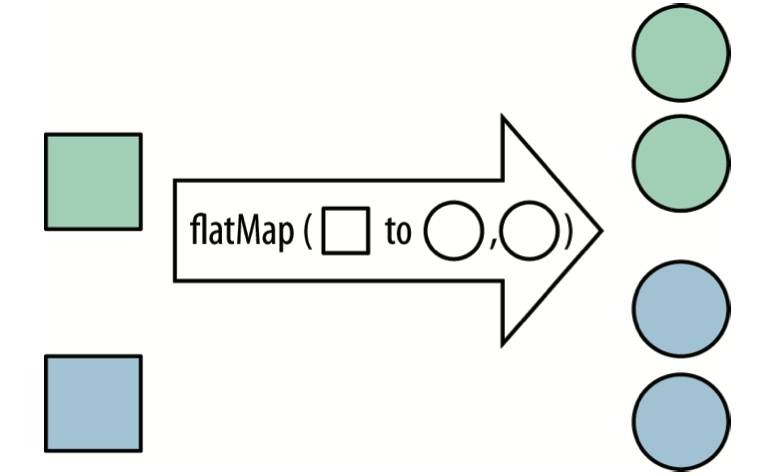
在不使用flatMap前你可能需要做2次for循环。这里调用了List的stream方法将每个列表转换成Stream对象, 其他的就和之前的操作一样。
Stream中常用的操作之一是求最大值和最小值,Stream API 中的max和min操作足以解决这一问题。
查找Stream中的最大或最小元素,首先要考虑的是用什么作为排序的指标。 以查找价格最低的店铺为例,排序的指标就是店铺的价格等级。
为了让Stream对象按照价格等级进行排序,需要传给它一个Comparator对象。 Java8提供了一个新的静态方法comparingInt,使用它可以方便地实现一个比较器。 放在以前,我们需要比较两个对象的某项属性的值,现在只需要提供一个存取方法就够了。
通常我们处理完流之后想查看一下结果,比如获取总数,转换结果,在前面的示例中你发现调用了 filter、map之后没有下文了,后续的操作应该调用Stream中的collect方法完成。
并发是两个任务共享时间段,并行则是两个任务在同一时间发生,比如运行在多核CPU上。 如果一个程序要运行两个任务,并且只有一个CPU给它们分配了不同的时间片,那么这就是并发,而不是并行。
这和顺序执行的任务量是一样的,区别就像用更多的马来拉车,花费的时间自然减少了。 实际上,和顺序执行相比,并行化执行任务时,CPU承载的工作量更大。
还是拿马拉车那个例子打比方,就像从车里取出一些货物,放到另一辆车上,两辆马车都沿着同样的径到达目的地。
当需要在大量数据上执行同样的操作时,数据并行化很管用。 它将问题分解为可在多块数据上求解的形式,然后对每块数据执行运算,最后将各数据块上得到的结果汇总,从而获得最终答案。
人们经常拿任务并行化和数据并行化做比较,在任务并行化中,线程不同,工作各异。 我们最常遇到的JavaEE应用容器便是任务并行化的例子之一,每个线程不光可以为不同用户服务, 还可以为同一个用户执行不同的任务,比如登录或往购物车添加商品。
流使得计算变得容易,它的操作也非常简单,但你需要遵守一些约定。默认情况下我们使用集合的stream方法 创建的是一个串行流,你有两种办法让他变成并行流。
读到这里,大家的第一反应可能是立即将手头代码中的stream方法替换为parallelStream方法, 因为这样做简直太简单了!先别忙,为了将硬件物尽其用,利用好并行化非常重要,但流类库提供的数据并行化只是其中的一种形式。
我们先要问自己一个问题:并行化运行基于流的代码是否比串行化运行更快?这不是一个简单的问题。 回到前面的例子,哪种方式花的时间更多取决于串行或并行化运行时的。
推荐: